3. Architecture¶
The Python code is highly modular, with testability in mind. so that specific parts can run in isolation. This facilitates studying tough issues, such as, double-precision reproducibility, boundary conditions, comparison of numeric outputs, and studying the code in sub-routines.
Tip
Run test-cases with pytest command.
3.1. Data Structures:¶
Computations are vectorial, based on hierarchical dataframes, all of them stored in a single structure, the datamodel. In case the computation breaks, you can still retrieve all intermediate results till that point.
Todo
Almost all of the names of the datamodel and formulae can be remapped,
For instance, it is possible to run the tool on data containing n_idling_speed
instead of n_idle (which is the default), without renaming the input data.
- mdl¶
- datamodel¶
The container of all the scalar Input & Output values, the WLTC constants factors, and 3 matrices: WOT, gwots, and the cycle run time series.
It is composed by a stack of mergeable JSON-schema abiding trees of string, numbers & pandas objects, formed with python sequences & dictionaries, and URI-references. It is implemented in
datamodel, supported bypandalone.pandata.Pandel.- WOT¶
- Full Load Curve¶
An input array/dict/dataframe with the full load power curves for (at least) 2 columns for
(n, p)or their normalized values(n_norm, p_norm). See also https://en.wikipedia.org/wiki/Wide_open_throttle- gwots¶
- grid WOTs¶
A dataframe produced from WOT for all gear-ratios, indexed by a grid of rounded velocities, and with 2-level columns
(item, gear). It is generated byinterpolate_wot_on_v_grid(), and augmented byattach_p_avail_in_gwots()&calc_p_resist().Todo
Move grid WOTs code in own module
gwots.- cycle¶
- cycle run¶
A dataframe with all the time-series, indexed by the time of the samples. The velocities for each time-sample must exist in the gwots. The columns are the same 2-level columns like gwots. it is implemented in
cycler.
3.2. Code Structure:¶
The computation code is roughly divided in these python modules:
- formulae¶
Physics and engineering code, implemented in modules:
- - orchestration¶
The code producing the actual gear-shifting, implemented in modules:
gridwots(TODO)scheduler(TODO)experiment(TO BE DROPPED,datamodelwill assume all functionality)
- scheduler¶
- graphtik¶
The internal software component
graphtikwhich decides which formulae to execute based on given inputs and requested outputs.
The blueprint for the underlying software ideas is given with this diagram:
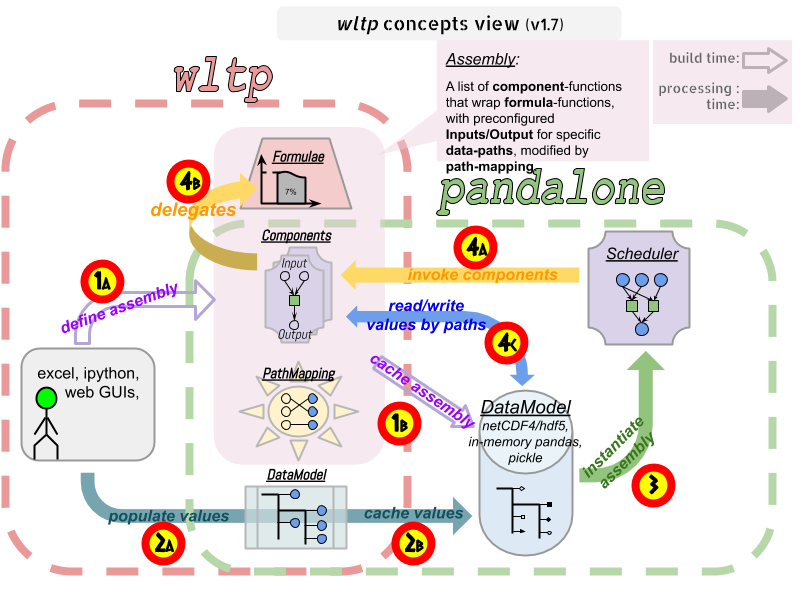
Note that currently there is no scheduler component, which will allow to execute the tool with a varying list of available inputs & required data, and automatically compute only what is not already given.
3.3. Specs & Algorithm¶
This program imitates to some degree the MS Access DB (as of July 2019),
following this 08.07.2019_HS rev2_23072019 GTR specification
(docs/_static/WLTP-GS-TF-41 GTR 15 annex 1 and annex 2 08.07.2019_HS rev2_23072019.docx,
included in the docs/_static folder).
Note
There is a distinctive difference between this implementation and the AccDB:
All computations are vectorial, meaning that all intermediate results are calculated & stored, for all time sample-points, and not just the side of the conditions that evaluate to true on each sample.
The latest official version of this GTR, along with other related documents maybe found at UNECE’s site:
4. Glossary¶
See also Architecture.
- WLTP¶
The Worldwide harmonised Light duty vehicles Test Procedure, a GRPE informal working group
- UNECE¶
The United Nations Economic Commission for Europe, which has assumed the steering role on the WLTP.
- GRPE¶
UNECE Working party on Pollution and Energy - Transport Programme
- GTR¶
Any of the Global Technical Regulation documents of the WLTP .
- GS Task-Force¶
The Gear-shift Task-force of the GRPE. It is the team of automotive experts drafting the gear-shifting strategy for vehicles running the WLTP cycles.
- WLTC¶
The family of pre-defined driving-cycles corresponding to vehicles with different PMR. Classes 1,2, 3a/b are split in 3, 4 and 4 parts respectively.
- AccDB¶
- MS Access DB¶
The original implementation of the algorithm in MS Access by Heinz Steven.
To facilitate searching and cross-referencing the existing routines, all the code & queries of the database have been extracted and stored in as text under the Notebooks/AccDB_src/ folder of this project.
- MRO¶
- Mass in running order¶
The mass of the vehicle, with its fuel tank(s) filled to at least 90 per cent of its or their capacity/capacities, including the mass of the driver and the liquids, fitted with the standard equipment in accordance with the manufacturer’s specifications and, where they are fitted, the mass of the bodywork, the cabin, the coupling and the spare wheel(s) as well as the tools when they are fitted.
- UM¶
- Kerb mass¶
- Curb weight¶
- Unladen mass¶
The Mass in running order minus the Driver mass.
- Driver weight¶
- Driver mass¶
75 kgr
- TM¶
- Test mass¶
The representative weight of the vehicle used as input for the calculations of the simulation, derived by interpolating between high and low values for the CO2-family of the vehicle.
- Downscaling¶
Reduction of the top-velocity of the original drive trace to be followed, to ensure that the vehicle is not driven in an unduly high proportion of “full throttle”.
- JSON-schema¶
The JSON schema is an IETF draft that provides a contract for what JSON-data is required for a given application and how to interact with it. JSON Schema is intended to define validation, documentation, hyperlink navigation, and interaction control of JSON data.
The schema of this project has its own section: code:Schemas
You can learn more about it from this excellent guide, and experiment with this on-line validator.
- JSON-pointer¶
JSON Pointer(RFC 6901) defines a string syntax for identifying a specific value within a JavaScript Object Notation (JSON) document. It aims to serve the same purpose as XPath from the XML world, but it is much simpler.
- sphinx¶
The text-oriented language, a superset of Restructured Text, used to write the documentation for this project, with similar capabilities to LaTeX, but for humans, e.g., the Linux kernel adopted this textual format on 2016. http://sphinx-doc.org/
- notebook¶
- jupyter notebook¶
- Jupyter¶
Jupyter is a web-based interactive computational environment for creating Jupyter notebook documents. The “notebook” term can colloquially make reference to many different entities, mainly the Jupyter web application, Jupyter Python web server, or Jupyter document format, depending on context.
A Jupyter Notebook document is composed of an ordered list of input/output cells which contain code in various languages, text (using Markdown), mathematics, plots and rich media, usually ending with the “.ipynb” extension.